



Wprowadzenie
W Navigatorze rozwiązania AI działają w 2 warstwach:
- Warstwa usług – metody API, które mogą być wywoływane do konkretnych zadań wdrożeniowych
- Warstwa implementacji w systemie Navigator – konkretne funkcjonalności systemu wykorzystujące usługi AI w określonych obszarach
Uczenie maszynowe zostało zaimplementowane dla systemów Windows 10 oraz Linux. Opis warstwy usług znajduje się w artykule Usługi AI w NAVIGATORZE
Implementacja usług AI w Navigatorze
Aby rozpocząć pracę z usługą AI, należy wprowadzić kilka zmian, które obejmować będą bazę danych oraz Navigatora. Na początku należy wprowadzić ustawienia w konfiguracji systemu, a następnie można przejść do ustawień na konkretnych obiektach w systemie.
Konfiguracja systemu
Konfiguracja usług AI odbywa się w konfiguracji systemu przez formularz Ustawienia > Pozostałe > Ustawienia. Konfiguracja systemu została dokładnie opisana w artykule Konfiguracja systemu

Włączenie usługi AI
Aby usługi AI były aktywne, należy w konfiguracji systemu ustawić właściwy adres serwera AI. Należy go podać w polu Adres URL do API AI

Dodatkowo należy ustawić uwierzytelnianie w usługa AI poprzez podanie loginu i hasła. Dane te są ustalane podczas wdrożenia i późniejsza ich zmiana może spowodować zablokowanie możliwości korzystania z tych usług.

Określenie zbioru uczącego
Zbiór uczący to zestaw dokumentów, na podstawie których uczona jest usługa. Domyślnie wartość ta wynosi 50.

Automatyczne odświeżanie modelu
Wszystkie modele ustawione mają automatyczne odświeżenie, które uruchamiane jest codziennie, przy pierwszym zalogowaniu do systemu. Aby wyłączyć/włączyć automatyczne odświeżanie należy zmienić stan checkboksa:

- odznaczony – wyłączone
- zaznaczony – włączone
Automatyczna podmiana załącznika po OCR BN
Po uruchomieniu OCR BN załącznik zostanie automatycznie zmieniony na edytowalny plik PDF zawierający warstwę tekstową

Długość okresu nauki w dniach
Parametr ten określa, jakie dokumenty będą brane pod uwagę przy uczeniu modeli AI. Domyślnie jest to 180 dni czyli do uczenia będą brane dokumentu które nie są starsze niż 180 dni.

Ustawienia w systemie
Rekomendacje na polach formularza
Usługa AI Text classification jest wykorzystana do rekomendowania wartości na wybranych polach formularza. Wyuczony model jest uruchamiany w procesie OCR-owania załączników. Po zakończeniu pracy OCR efekt na takim polu będzie następujący:

Tworzenie modelu
Aby utworzyć model dla konkretnego pola należy zaznaczyć opcje Pokaż rekomendacje.

W tej chwili opcja jest dostępna dla pól systemowych: kontrahent, kontrahent edycja, właściciel, firma, kategoria, typ oraz atrybutu typu autowyszukiwanie.
Po kliknięciu „Zapisz” model jest uczony (w tle). Zajmuje to ok. 20 sekund. Po tym czasie po zakończeniu procesu OCR na dokumencie powinny się pojawić rekomendacje w tym polu. Jeżeli się nie pojawią należy odczekać dłużą chwilę (ok. 10 min.). Być może proces uczenia jest dłuższy (np. wskutek większego zbioru uczącego lub obciążenia serwera).
Ważne:
- Model będzie działać jeżeli w bazie znajduje się dostateczna ilość prawidłowo wprowadzonych dokumentów. Najlepiej podać więcej niż 20 przykładów dla każdej klasy (np. 20 dokumentów z uzupełnionym właścicielem)
- Najlepiej, żeby rozkład w każdej klasie był zrównoważony (np. faktury dekretowane na różnych właścicieli)
- System Business Navigator pobiera do procesu uczenia tylko najnowsze dane. Pod uwagę brane są tylko dokumenty, które mają załączniki, które są z OCR-owane (mają dane w [OcrText] w tabeli [Fi]).
- Model zapisuje się na serwerze usług AI z nazwą KodFirmy_TypPola_IdPola (np. FRUCTON_FlSy_5, FRUCTON_FL_8660), gdzie:
- KodFirmy – CompanyCode z tabeli [Sg]
- TypPola – FlSy dla pól systemowych, Fl dla atrybutów lub Di dla słowników
- IdPola – ID z tabeli FlSy, Fl, lub Di
- Nie ma możliwości usunięcia modelu z serwera AI z poziomu systemu Business Navigator. Aby przestać z niego korzystać wystarczy odznaczyć pole Pokaż rekomendacje. Aby usunąć model z serwera AI należy użyć API.
- W celu aktualizacji modelu należy kliknąć „Resetuj model” (model jest usuwany i proces uczenia zaczyna się od nowa).
OCR BN
Pod nazwą silnika OCR „BN” znajduje się zestaw usług AI: OCR, Text Classification, Data capture. Dodatkowo system wykonuje inne procesy automatyzujące (np. ładowanie dokumentu wzorcowego, pobieranie danych kontrahenta z GUS etc.)
Silnik wybieramy dla określonego typu dokumentu.

Kroki w ramach procesu OCR wykonywanego przez silnik BN:
- OCR
- Jeśli załącznik nie zawiera tekstu (nie jest przeszukiwalnym PDF-em albo nie został wcześniej OCR-owany) wysyłany jest do API AI (/ocr)
- zwrócony przeszukiwalny PDFA jest zapisywany w bazie Navigatora w tabeli „Fi” w kolumnie „PdfFile”)
- Data capture
- Plik PDFA wysyłany jest do procesu API AI (./data_capture/general/1/predict). API zwraca plik xml oraz czysty tekst pliku.
- Czysty tekst zapisywany jest w bazie Navigatora w tabeli „Fi” w kolumnie „OcrText”
- Plik XML zapisywany jest w bazie Navigatora w tabeli „Fi” w kolumnie „OcrData”
- Text classification
- Czysty tekst wysyłany jest do procesu „Text classification” API AI (/text_classification/{classifier_id}/predict). Proces jest wykonywany dla wszystkich modeli zdefiniowanych we wszystkich formularzach obszaru Dokumenty
- Decyzja jaka Firma, Typ dokumentu, Kategoria:
- W przypadku wywołania OCR poprzez „Dodaj wiele z OCR” silnik wykorzystuje znaną z kontekstu wywołania kategorię i typ. Nawet jeżeli Text Classification zwrócił inną rekomendację dla tych pól nie jest ona brana pod uwagę
- Podobnie w przypadku wybranej firmy, ona również będzie ustawiana dla dokumentu niezależnie od wskazania Text Classification
- W przypadku użycia „AI hot folder” system będzie określał Typ, Kategorię, Firmę na podstawie najwyżej rekomendowanego wskazania Text Classification. Uwaga! Każde z tych pół przynajmniej na jednym formularzu musi być oznaczone „Wstaw pozycję najbardziej prawdopodobną”.
- Ustawienie kontrahenta
- Data capture zwraca 2 NIPY (pola VATID i VATID1). Jako kontrahent będzie wytypowany ten który nie jest „naszą firmą”, tzn. nie jest przypisany do którejś z firm (Ustawienia -> Kartoteki -> Firmy -> Edytuj -> Kontrahent).
- Jeżeli istnieje kontrahent o tym NIP w kartotece Kontrahenci wstawiany jest do formularza
- Jeżeli nie istnieje kontrahent o tym NIP w kartotece kontrahenci jest on zaczytywany z bazy GUS
- Uzupełnienie nieuzupełnionych pól wyboru na podstawie rekomendacji Text classification
- Uzupełnienie nieuzupełnionych pól na podstawie pliku Data capture (kolumna „OcrData” w tabeli „Fi”)
- Jeżeli dla kontrahenta dla wybranego typu dokumentu istnieje model szczegółowy Data capture uruchamiana jest usługa AI ./data_capture/templates/{template_id}/predict. Nieuzupełnione dotychczas pola są uzupełniane wartościami zwróconymi przez tą usługę.
- Uzupełnienie reszty nieuzupełnionych pól na podstawie dokumentu wzorcowego kontrahenta danego typu (jeżeli istnieje)
Dodatkowe uwagi:
- Aby usługa Text classification wybrała Typ należy w co najmniej jednym formularzu dla pola „Typ” wybrać opcję „Pokaż rekomendację” oraz „Wstaw pozycję najbardziej prawdopodobną”.
- Jeśli klasyfikator wskazał najbardziej prawdopodobny typ, rekomendacje są podpowiadane tylko dla tego typu (przykład: Jeśli na typie „Faktura zakupu” (formularz “Faktura zakupu”) mam zaznaczoną opcję „Wstaw pozycję najbardziej prawdopodobną” dla pól „Typ” i „Kategoria” a klasyfikator wskazał, że to typ „Faktura sprzedaży” (formularz “Faktura sprzedaży”), na którym nie mam zaznaczonej tej opcji, to pola nie zostaną uzupełnione.
- Dokument bez typu i kategorii nie zostanie utworzony (komunikaty „Nieznany typ dokumentu.” lub „Nieznana kategoria dokumentu.”).
- Opcje „Hot folder” i „Dodaj wiele z OCR” tworzą nowy dokument i zapisują go w bazie. OCR-owanie na formularzu nowego dokumentu tylko uzupełnia pola (nie tworzy nowego dokumentu ani nie zapisuje wartości do bazy).
AI hot folder
AI hot folder jest najbardziej zaawansowanym scenariuszem procesu opisywanego powyżej. Z punktu widzenia użytkownika wrzuca on skany dokumentów w jedno miejsce. Następnie system sam rozdziela je do odpowiednich szufladek (kategorii) wykorzystując do tego celu usługi klasyfikacji tekstu.
Poniżej w skrócie opisano co system robi po dodaniu pliku do AI hot folder:
- Wykonuje proces OCR (przekształcanie obrazu w tekst)
- Określa 3 kluczowe cechy na postawie klasyfikacji: Firma, Typ dokumentu, Kategoria. Na podstawie tych cech rozmieszcza pliki do odpowiednich kategorii
- Uruchamia proces tworzenia dokumentu na bazie pliku

Szczegółowo kroki opisane są w punkcie OCR BN powyżej.
Na razie usługa działa w obrębie dokumentów.
Ustawianie modelu szczegółowego Data capture
Model szczegółowy data capture pozwala na przechwycenie dowolnej wartości z dowolnego typu dokumentu.
Aby rozpocząć pracę z modelem szczegółowym należy najpierw aktywować przycisk „Aktualizuj model szczegółowy”, poprzez dodanie go do menu dokumentu, który będziemy poddawać procesowi „OCRowania”. Aby włączyć przycisk, należy przejść do modułu Ustawienia -> Personalizacja -> Menu, wybrać z listy te menu, które jest podpięte pod dokument, a następnie kliknąć Edytuj. (Domyślnie zawsze jest to Menu systemowe Dokumenty). Po otwarciu formularza, należy z drzewka po lewej wybrać Więcej, a następnie kliknąć Więcej -> Dodaj i w formularzu dodawania nowego przycisku skonfigurować przycisk jak poniżej. Na końcu klikamy Zapisz. Więcej o konfiguracji menu można dowiedzieć się tutaj.

Aby wytrenować model szczegółowy należy:
- Prawidłowo wprowadzić min. 3 dokumenty (załącznik musi być musi być “zOCRowany” czyli mieć warstwę tekstową, dane wprowadzone do formularza muszą być prawidłowe)
- Dla każdego z dokumentów należy kliknąć opcję “Aktualizuj model szczegółowy”. Ten proces może trwać nawet do kilku minut w zależności od ilości pół na formularzu oraz liczby stron dokumentu.
Po tych dwóch krokach model jest już gotowy. Aby go przetestować należy wykonać proces OCR dla kolejnego dokumentu.
Podczas procesu OCR system:
- Najpierw wykona data capture w oparciu o model ogólny (./data_capture/general/1/predict)
- Następnie wykona data capture w oparciu o model szczegółowy i uzupełni te pola, które uda mu się przechwycić (./data_capture/templates/{template_id}/predict)
Na poniższej animacji zaprezentowano jak przechwycić niestandardowe informacje z faktury.
Szczegółowe informacje odnoście trenowania modelu szczegółowego
Trenowanie modelu szczegółowego odbywa się poprzez usługę AI /data_capture/templates/{template_id}/fit
Pola formularza, które są wysyłane do uczenia:
- numer obcy (kolumna [ForeignNumber] z tabeli [Do])
- data dokumentu ([DocumentDate])
- data płatności ([PayDate])
- numer rachunku bankowego kontrahenta (kolumna [AccountNumber] z [CoAc])
- nip kontrahenta (kolumna [NIP] z [Co]) zarówno z pola 'Kontrahent’ jak i 'Kontrahent edycja’
- waluta (kolumna [Symbol] z tabeli [Cu])
- opis ([Description])
- kwota netto ([Net])
- kwota vat ([Nat])
- kwota brutto ([Gross])
- wszystkie atrybuty (kolumna [Text] z [FlVa]) typu:
- Pole tekstowe
- Wielowierszowe pole tekstowe
- Data
- Data i czas
- Liczba
- Liczba zmiennoprzecinkowa
Szczegółowe informacje odnośnie odczytu informacji z modelu szczegółowego
Krok 1:
Na początek odpytywana jest usługa ./data_capture/general/{model_id}/predict dla modelu faktury. Zwraca ona plik XML, który wygląda tak:
- numer obcy (nazwa pola w XML ABBYY: _InvoiceNumber)
- data dokumentu (_InvoiceDate)
- data płatności (_DueDate)
- data zdarzenia (_FactDate)
- kontrahent (na podstawie NIPu z _VATID lub _VATID1 w zależności od firmy)
- numer konta rachunku bankowego kontrahenta (_BankAccount)
- elementy (_LineItems):
- jednostkę miary (_UnitOfMeasurement)
- stawkę vat (_VATPercentage)
- ilość (_Quantity)
- asortyment (_Description)
- wartość brutto (_TotalPriceBrutto)
- wartość netto (_TotalPriceNetto)
- wartość vat (_VATValue)
- stawki VAT:
- stawka vat (_TaxRate)
- wartość netto (_NetAmount)
- wartość vat (_TaxAmount)
- wartość brutto (_GrossAmount)
Krok 2:
Następnie system sprawdza, czy istnieje model szczegółowy dla tego kontrahenta i tego typu dokumentu (./data_capture/templates/list). Jeżeli jest, odpytywana jest usługa ./data_capture/templates/{template_id}/predict. Dane, które zwróci są dopisywane do pliku XML uzyskanego w kroku 1 tylko w przypadku gdy model ogólny jej nie uzupełnił. Dodatkowo dopisywane są gałęzie:
- opis (_Description)
- waluta (_Currency)
- atrybuty (_Attributes)
Tak przygotowany plik jest zapisywany w tabeli „Fi” w kolumnie „OcrData”. Z tego pliku są uzupełniane dane w formularzu dokumentu.
Przechwytywanie danych z załącznika
W wersji 6.1 NAVIGATORA dodana została funkcjonalność łatwego uczenia systemu poprzez model szczegółowy, które fragmenty dołączonych plików, np. faktury, odpowiadają polom na formularzu. Jeżeli mamy niestandardowe pola, które chcemy przenieść z załączonego pliku na formularz to musimy nauczyć system z którego miejsca brać te dane.

W celu nauczenia modelu szczegółowego wystarczy wskazać pole, do którego chcemy pobrać dane, zaznaczyć interesujący nas obszar na załączniku i uruchomić procedurę przechwytywania. System w tle przypisze odpowiedni fragment załącznika do pola na formularzu dla wybranego kontrahenta. Użytkownik powinien po wykonaniu przypisania uruchomić procedurę Aktualizacji modelu szczegółowego opisaną w poprzedniej sekcji.
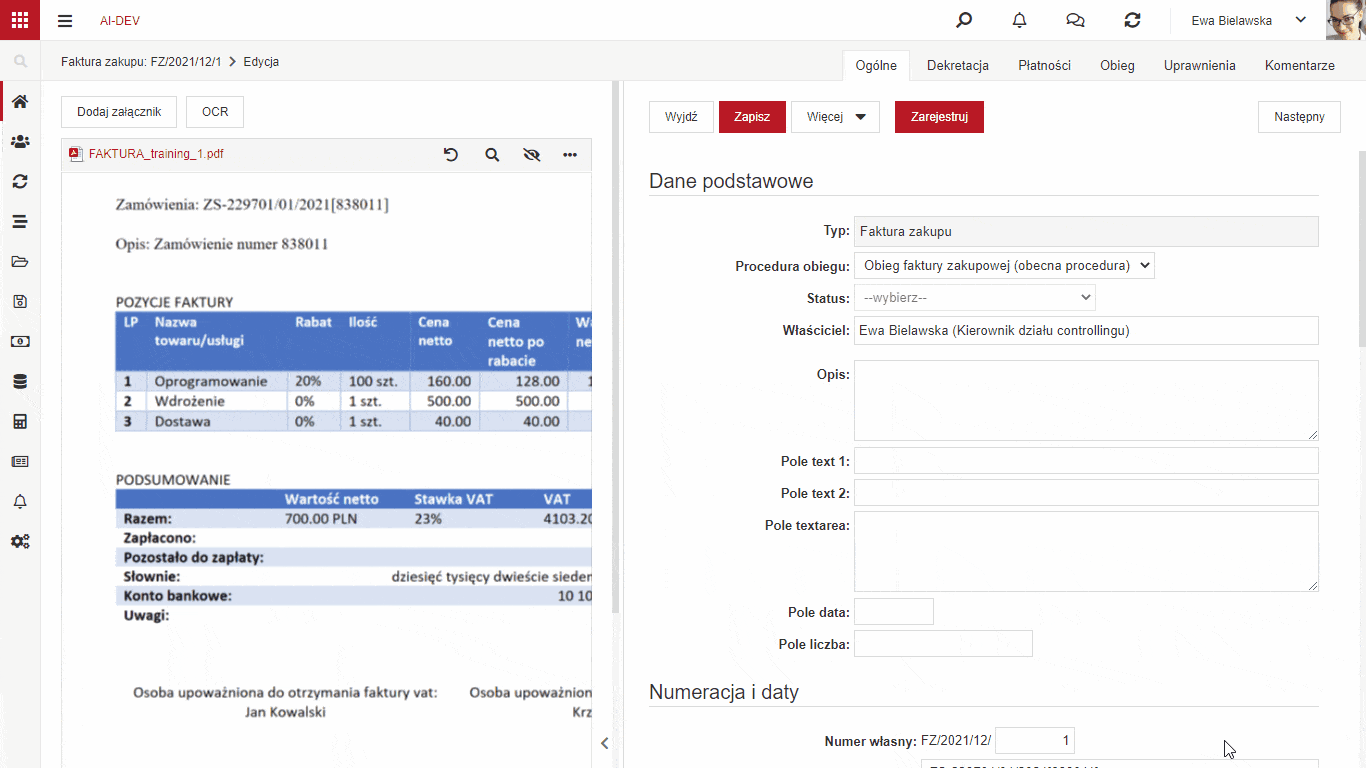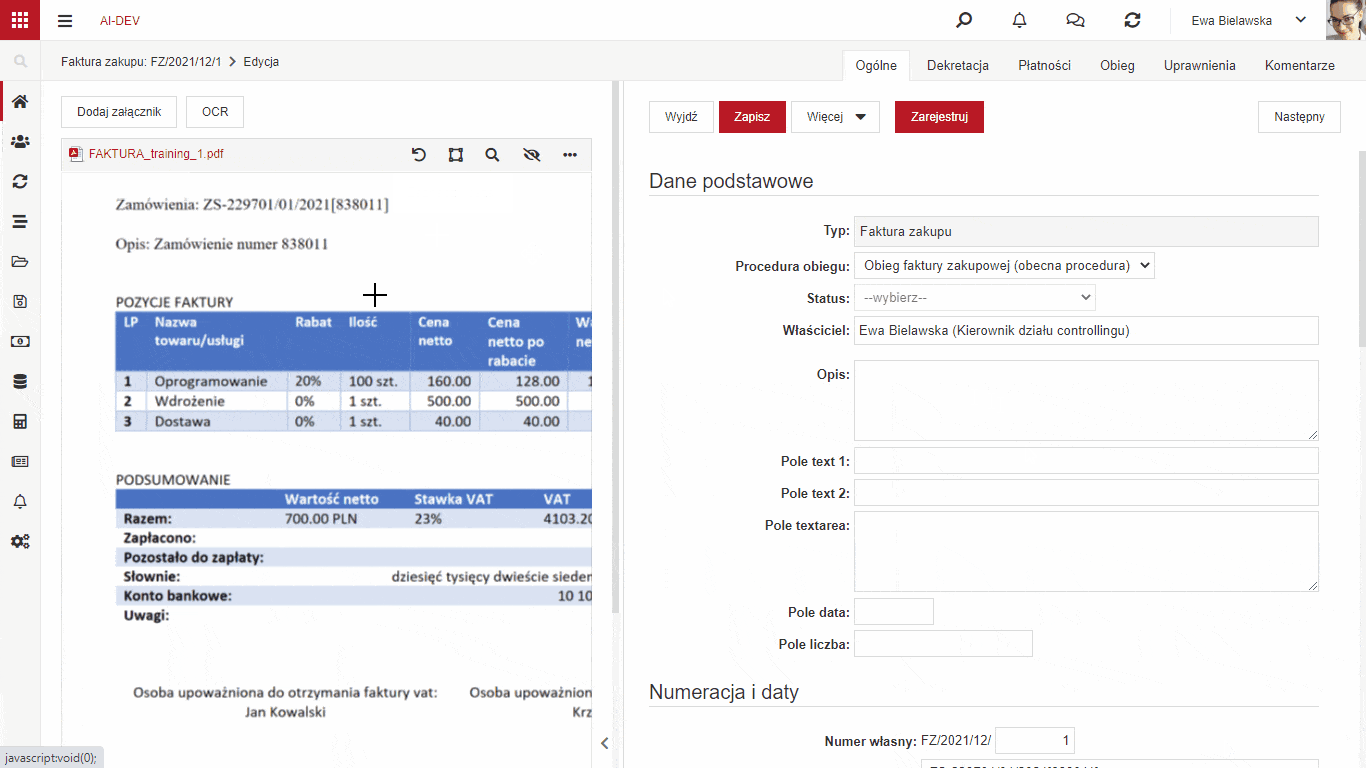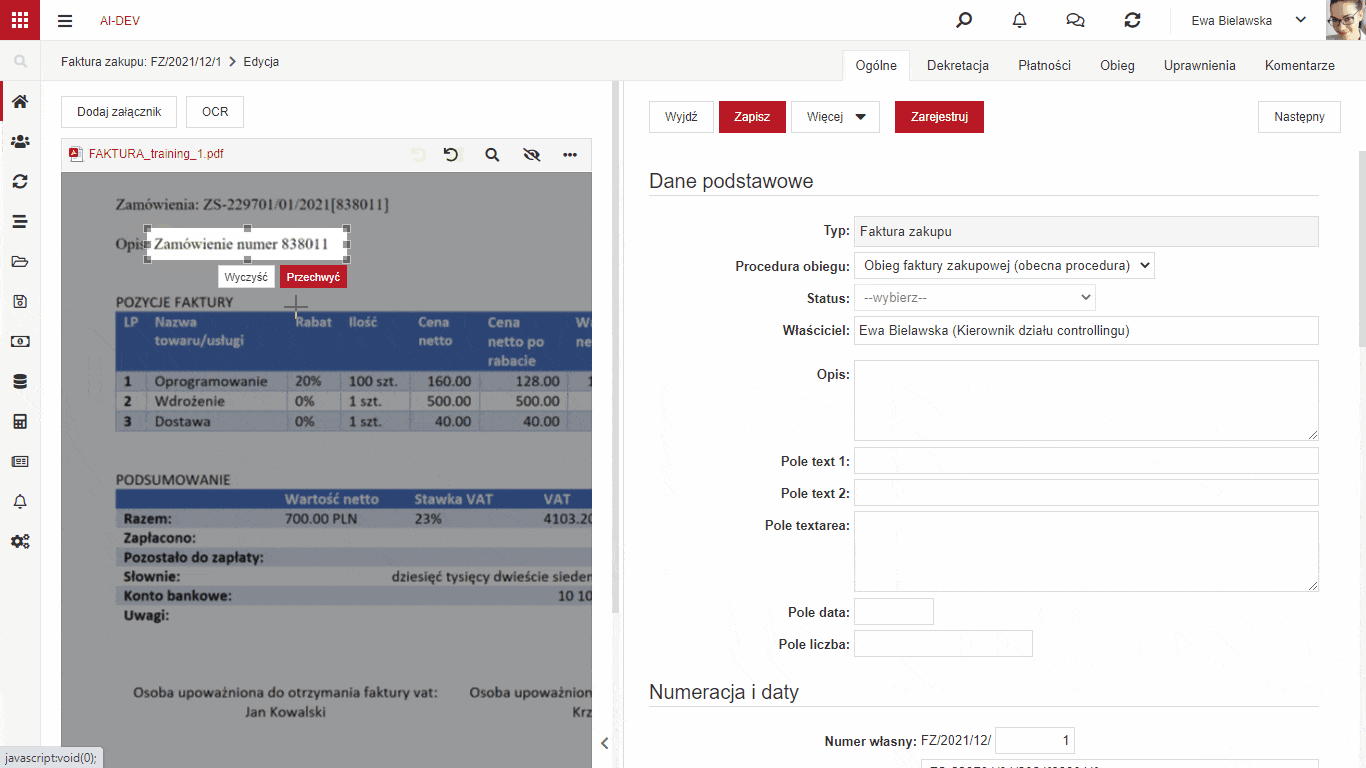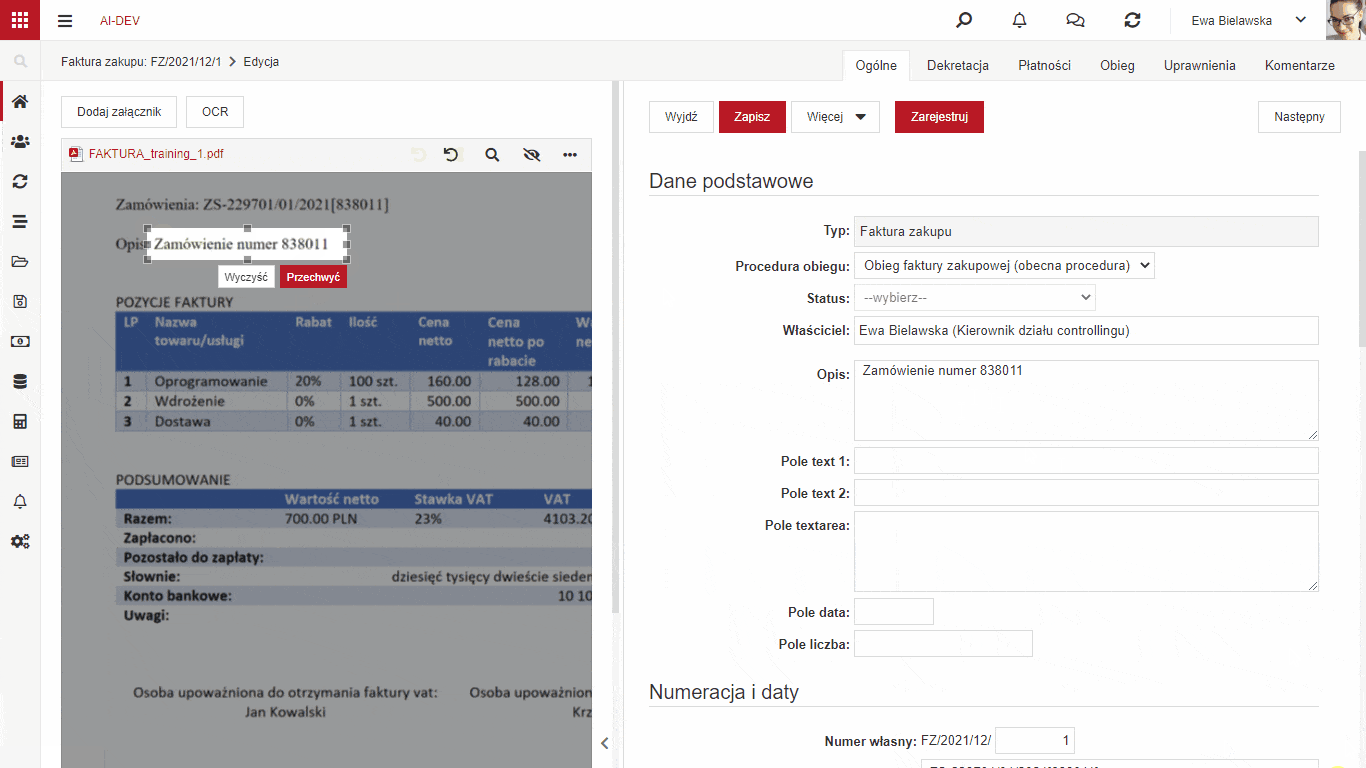
Aby funkcjonalność mogła zostać uruchomiona załącznik musi być plikiem z warstwą tekstową. Oznacza to, że należy uruchomić procedurę OCR na wgranym załączniku która doda warstwę tekstową do pliku jeżeli jej brakuje.